
The Fractal Map and Impossible Symmetry
Is a 1:1 digital map of the earth attainable?


The concept of digital twins and world scale mapping with granular detail always evokes the writings of Jorge Luis Borges, particular his brief text On Exactitude in Science:
“In this empire, the art of cartography was taken to such a peak of perfection that the map of a single province took up an entire city and the map of the empire, an entire province.”
The quote is well known, but what is lesser known is author Umberto Eco’s disproportionately thorough response, written in the 1982 essay On the Impossibility of Drawing a Map of the Empire on a Scale of 1 to 1. Eco highlights several assumptions about this hypothetical map of the territory, such as saying it could be divided among many sheets of paper that can be conjoined, but also that the map is not the territory itself or does not modify the territory as a result of mapping it. He then argues that such a map, in any case, ends up as an impossible paradox.
Impossible space
A core element of Eco’s rebuttal is that there is simply a problem of physical storage: how can a 1:1 map, for example of Monaco, exist? Must it be draped on top of Monaco? Mounted on posts several meters above the surface (thus blocking the sun and modifying the territory)? Should the copy of it be laid out in the Sahara? In 1982, what perspective he was lacking is the concept of say a Postgres database, living on the cloud in S3.
Huge datasets rest in just such a state: LiDAR covering the surface of France, global street level imagery and 3d reconstructions, the crowdsourced map of the world, and more. From Google to Wikipedia and OpenStreetMap, an ever growing body of all the world’s information is digital—infinitely small compared to the physical size of all the screens required to show it simultaneously.

Borges often wrote fondly of libraries—the analog type, which still charm us today, but something in his poetic explorations of infinity and labyrinths connects these to the digital realm of information. Google Books has scanned over 40 million titles—books, magazines, and more—that are available for text search, an eternal library in the cloud with no tangible corridors or atriums (unless you count data centers).
Meanwhile, some back of the napkin estimates for the size of Google Maps hover around 43 petabytes in 2016, so maybe we call it 50 petabytes today with ongoing growth. As a wild guess, a data center might on average hold 100 petabytes, so all of the Google’s Map (which omits likely a huge amount of geospatial data available) might require half of a warehouse like Meta’s in Eagle Mountain, Utah.
“There are still some remains of this map in the western desert,” writes Borges. Indeed.

Impossible process
With data centers in remote places like the Utah high desert, it seems the physical storage problem of a 1:1 map is trivial. Eco points out another challenge, however: that of keeping the map updated. In his world, the issue is that if a 1:1 physical map is draped over the world, then it becomes part of the world and the map no longer reflects the world (a sort of infinite regress of a map of the world with the map of the world in it).
Again, having solved this with digitization, the source of Eco’s problem is not the physicality of the map—the spatial aspect—but the temporal aspect does remain. He suggests how to address it:
either (i) by producing every single part of the map, once all the stakes were in place, in a single moment of time at every point in the territory, so that the map would remain faithful at least in the instant when it is completed (and perhaps for many successive hours);
or else (ii) by arranging for ongoing correction of the map based on the modifications of the territory.
We can summarize it with what we all know: a map published today is outdated tomorrow. This is particularly true as the scale of the map expands: a map of Santa Fe, New Mexico may be valid for weeks or months if no construction happens, if businesses don’t close or open… essentially the rate of change may be slower on a small scale. As soon as we include all of North America, the probability of change happening within minutes after publication skyrockets.
To quote Chevy Chase’s character, the sage handyman, in Hot Tub Time Machine: “Do you understand what I'm saying? The whole system can go haywire if you change one little thing.”

Well, the system does not necessarily go haywire—a fun etymology by the way—but on a small scale, your map becomes out of date for local users. On a large scale, the same happens, but less predictably, and keeping it updated in a deliberate way might be like a game of whack-a-mole. So Eco captures this in his second point above: the outdated map, sooner or later, needs ongoing correction of the map based on the modifications of the territory, or in other words, constant updates based on what changes.

In Google’s Beyond the Map blog series (part 1, part 2), the Google Maps team gives “a closer look at how we build maps that keep up with the ever-evolving world”. Google describes some of their methods for keeping up with the ever-evolving map:
[we] use data from more than 1,000 authoritative data sources around the world like the United States Geological Survey, the National Institute of Statistics and Geography (INEGI) in Mexico, local municipalities, and even housing developers
And user-contributed content, with crowdsourcing as a powerful tool:
we receive more than 20 million contributions from users every day–from road closures, to details about a place’s atmosphere, to new businesses, and more
Google Street View is also key:
Advances in our machine learning technology, combined with the more than 170 billion Street View images across 87 countries, enable us to automate the extraction of information from those images and keep data like street names, addresses, and business names up to date
The link to automated extraction from Street View goes on to cite the importance of deep learning, citing how it is “impossible to manually analyze more than 80 billion high resolution images.” A similar explanation is made about extracting buildings from satellite imagery.

The heart of this all is that Eco points to instant expiration of data and continuous ingestion of updates as limitations, but Google and other map product providers have solved this with:
Crowdsourcing of user contributed updates
Machine learning and AI generated map data
Continuous Integration/Continuous Delivery (CI/CD) of map data
Impossible scale
Eco does not directly address the concept of scale. Some of his critiques may allude to it. One condition about how a map must be constructed states:

…and here we focus on this word, perceptible. He sets out two other limitations of mapping later:
Every 1:1 map always reproduces the territory unfaithfully.
At the moment the map is realized, the empire becomes unreproducible.
He goes on to say that achieving a 1:1 map would cause an empire to become “imperceptible to enemy empires...to itself as well”. Taken very literally here, Eco is claiming that draping the map, in a physical sense, over the earth, would obscure the earth, like shrouding a couch under a blanket. Thinking more abstractly, we could guess he also means that the details are too many, and can never be precise or comprehensive, and measurements may not be the same when taken from one moment to another.

This comes to explore the idea of the world as fractal. Map data is extremely fractal. Let’s look at two examples: the world itself, and map data.
There is a rather famous scenario called the Coastline Paradox which looks at how when measuring the coast of Britain, the more precise the measurement gets, the longer the coastline is. If we measure every little detail of a cliff by the water, we can get extra centimeters as the texture shifts. If we skip some of the small divots and nooks, we end up rounding to a smaller number.

Notice the stylized image above, how the stones have rather smooth edges. Can you count the fringes in the leaves of the palm trees? The style effect has simplified much of the geometry. It becomes something of an Impressionist take on reality, excluding some details, even embellishing others.

Now look again, at the original, and see how much more detail there is. In terms of geometry or geospatial data, or image processing, and many other systems based on geometry, a complex shape can be simplified:
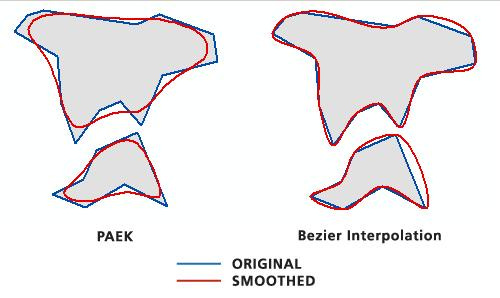
The fact is, everything we see, even with our own eyes, is simplified geometry. We do not perceive every hair on someone’s head, but see a collective mop. We see a tabletop as rectangular, without noticing the miniscule curvatures in its edges that you may see up close. In map data, many of these tiny details are imperceptible in reality but could be measured digitally, to at least a large degree. As Eco says, the map is always unfaithful, and making the map can mean making things perceptible that we do not notice in the physical world. And at the same time, the world becomes imperceptible: we realize the limits of our ability to map it at all.

The coastline of Britain in such a case, becomes infinite. Switzerland as we see above, because its borders follow rivers and mountain ridges, are also a problem of infinite precision to both measure and visualize. Representing a coastline in terms of millimeters is difficult and impractical, if not impossible—but at ever larger scales, maps struggle to be accurate, creating a sense of insecurity to those who build them. We can look at Microsoft’s AI-generated building dataset, visible in Meta’s Rapid editor, and see how it makes neat geometry out of buildings in satellite imagery, favoring 90 degree angles and ignoring the fractal reality.

Much of fractal geometry is explored by Benoit Mandelbrot’s algorithms, but looks at fractals in nature, like the coastline, in a way that is very neat and repetitive like Fibonacci sequences might be. In much of map data, when we get to infrastructure and cities, we still have fractal geometry but with perhaps more randomness and less order, making it even harder to map accurately, and less reliable to substitute with predictive data—faking of reality by reusing common patterns.
Impossible reality
Eco cites the Latin phrase “nihil maius cogitari possit”: nothing greater can be conceived. He speaks to the spatial limits of a map, in that the empire itself is the largest thing so the map can only match its physical size—but could also use maius to reference to excellence and precision rather than size. In fact, he is likely borrowing from Anselm of Canterbury, the medieval saint and bishop who used this in his argument for existence of God, stating that the most perfect thing that we can imagine equates to divinity. And so in terms of the map, we consider the most perfect map in terms of geometry that we can imagine as the standard for what a true 1:1 map would be.
GPS is often only accurate to something like 5 meters on a smartphone. High resolution commercial satellite imagery can reach 15cm per pixel, but then needs to still be geo-aligned to something that may be meters in accuracy. Then we have the problems of which coordinate systems are used and how spherical geography may compare against how we display a 3d model of buildings, in regards to shape, size, relative position.

Much of what happens when spatial data becomes super realistic and accurate is disappointing to some: it’s faked. This is not a deception, perhaps, but more of a strategy. This is where geospatial data and spatial computing, as often, borrow from advances in computer vision.
Consider the artistic school of Realism, “the accurate, detailed, unembellished depiction of nature or of contemporary life”. Realism, like empirical collection of map data and curation of digital twins, “rejects imaginative idealization in favour of a close observation of outward appearances.” And yet art of this school, despite striving for its ideals, has a generative aspect in that it references a real scene but fills in the gaps with assumptions, with projections of reality that look believable.

Advances in computer vision in the past few years have shared this philosophy of attempting to adhere to presenting reality, even when completely fabricated, in a believable, almost deceptive way. Image-to-image diffusion models can take gaps in an image—blank space, lack of color, low quality—and intelligently guess at how to enhance it.

The same thing often happens in terms of map data: super-resolution of satellite imagery using similar techniques to the bottom row above, colorization like in the top row, or like the middle rows, filling in gaps with guesses. Even manually tracing map data from aerial imagery, humans make assumptions when things get blurry that act just like the uncropping and inpainting methods shown above.
Looking at point clouds, we see some impressive advancements in 3d modelling of the natural or built world, direct from a visual or laser sensor, but with many gaps. Software then fills these in, whether in colorization, improving shapes and form, or just filling in blanks.

This starts to be similar to generative AI. However, it is also making a prediction, and it also may be doing recognition. In regards to map data, we could conceive of a model that recognizes the object and its context, let’s say in 2D nadir drone imagery: urban apartment buildings surrounded by sidewalk and grass. Then, where trees may obscure the view, a 3D model with texture and color may be partially constructed, but the model could predict that the visible sidewalks actually continue and conjoin under the tree, with same width and linear shape, and the rest of the surface has grass. Then it would generate exactly this using elements of other grass and sidewalk it can see. Voila: we have a more complete map, and it might be realistic—but it’s not real or true.

Coming back to Umberto Eco, we can see that this idea of AI relates back to perception: using tools that overcome a lack of omniscience on the part of the surveyor (data collector) or purveyor (data provider) means using a near-truth as the data, to be good enough for practical purposes, but which makes the map become less a clone of reality and almost a sort of reverse engineered fork of reality.
“An empire that achieves awareness of itself in a sort of transcendental apperception of its own categorial apparatus in action,” writes Eco about what a self-aware map would be. It’s a mouthful, but let’s interpret this as something like “artificial intelligence, when building a map of the territory, becomes so focused on succeeding in its mission, and so well acquainted with the patterns of the world, that it will continue to map accurately, through prediction and generation, even what it cannot see.”
Umberto Eco’s writings on Hyperreality may describe what we begin to see when uncertainty about truth in the term “ground truth” still yields impressive guesses about what the ground truth could be or should be. From a Wikipedia definition:
Hyperreality is seen as a condition in which what is real and what is fiction are seamlessly blended together so that there is no clear distinction between where one ends and the other begins. It allows the merging of physical reality with virtual reality (VR) or augmented reality (AR), and human intelligence with artificial intelligence (AI).

Impossible Symmetry
Digital twins of the world enable end users to have a hyper-accurate or hyper-precise clone of reality. Whether this is for urban planning, disaster response, gaming, navigation, or world domination, this idea of a digital twin is not much different from past trends of “machine readable maps” or “HD maps”. The idea behind all of them is some aspect of deeply capturing reality—down to the fractal details—or leveraging hyperreality to fill in the gaps.
Mobile mapping devices that scan textures and colors are one form of collecting this sort of data, alongside others like the aforementioned French national LiDAR program or apps for iPhones. All of these methods of reality capture do in fact map a local scene. Leica’s device makes a 3D model but takes additional steps to georeference it, while using something like DroneDeploy or Pix4D may be more automated when trying to use this data alongside something like OpenStreetMap vector data.
It quickly becomes obvious that every data collection method and category of map data has tradeoffs, and the only way to build an actual digital twin is to conflate all these datasets. Even then, is it really a twin? Whether because it misses the true fractal (infinite perhaps) details, uses artificial color sampling, generates data to interpolate gaps, or even just the fact that your building model has no complementary data about the electrical systems, individual bricks, or other micro-components… making a twin seems like a fractal challenge all in itself.

We showed that digital storage has revolutionized 1:1 data size, creating a new invisible world, we showed that ongoing updates are somewhat doable, and we showed that even the small details can be guessed at enough to achieve the goal of a map, even if not reflecting absolute truth.
Eco’s cryptic comments about the empire achieving some enlightened self-awareness may drive home the point, that it is possible to make a 1:1 map, but only in the impossible scenario that the map essentially consists of, rather than reflects, the human understanding of the world.
Maps for augmented reality, which rely on something like digital twins, approach this impossibility. If an AR headset has cameras on it, constantly performing SLAM processing, then it is seeing the world simultaneously with its user, and possibly referencing an existing model.

This is similar to how Niantic Lightship VPS and Google ARCore Geospatial API function in places where user contributed videos or Google Street View already exists as a foundational reference. Or how a self-driving car might use digital HD maps as a set of handrails, alongside its onboard camera. Visually, what the camera sees is checked against the archives and what it has seen.
Symmetry is what this kind of mapping aims for: not mapping in a way such that the map is symmetrical to the world, but in a way that the map is symmetrical to what humans know about the world.
Impossible Knowledge
The vision aspect is fundamental, but not revolutionary. This is perhaps where AI comes into play again: if the machine can develop an understanding of the scene in tandem with a user, and perhaps develop a better, more mathematical and physics-based comprehension to enhance what the human already knows, then as far as a human can tell, the scene is mapped 1:1.
Let’s approach this from a different direction. In the 2014 film Ex Machina, the humanoid robot’s mind is built by giving an algorithm access to all of human knowledge, seemingly on some platform that is a cross between Google and Facebook. The machine learning uses as its study material the set of facts about the world, examples of conversation, use of language, behavioral quirks of people, their preferences. The machine becomes aware and intelligent—with its own motivations—as a result of crunching all available textual data (and more probably), in order to mimic human life and then kick of the training wheels and start living.
This AI is sort of an anthropology, linguistics, literature, and psychology enthusiast. ChatGPT is not too different—it generates things as a result of referencing all the examples out there.

A similar AI could start from a different dataset: instead of having access to all the search results, libraries, encyclopedias, chat groups, and knowledge bases of the world, imagine the AI has access to all existing spatial data, as well as millions or billions of cameras that are effectively a live feed from human eyes living their daily life.
This AI is a geography enthusiast, as well as having interests in architecture, engineering, environmental science, biology, atmospherics, economics, and more. Certainly similar to others and an endless list of categories about what it observes. But if it’s mission is to build a model of the world, then it has access to all of human real time knowledge about the spatial makeup of the world, and yet with a better ability to log, centralize, synthesize, and conflate all that data.
In the end, an AI that was crunching a feed of all the spatial experiences that humans have, would end up being an aggregate of all human spatial knowledge. It would, as far as we could ever judge, be the perfect map, because it knows everything we know (and maybe guesses a bit more beyond what we can provide).
Nihil maius cogitari possit
So is Umberto Eco correct? Is Borges really writing about a myth, that will always be a myth?
Because human knowledge of the world prevents us from defining what exactly is 1:1 mapped, perhaps we either can never achieve it, or we can define it however we like. Perhaps only a map slightly better than the best map humans can conceive of is possible. And even with the most powerful AI to synthesize it all, perhaps it is crowdsourcing—the collaborative streaming of volunteered data—that can revive the map from one moment to the next. Nihil maius cogitari possit…